
Simplifying Data Pipelines With Mage Data Integrations
How to Use Mage's No-Code Data Integrations in a Standard Pipeline


What are Mage Data Integration Blocks
Mage includes no-code and low-code blocks for connecting to data sources called Data Integrations. Initially, Mage only supported using these blocks in Data Integration Pipelines. They’ve since enabled them to be used within standard pipelines as a preview feature. Data Integration Blocks allow you to connect to a database, data warehouses, Salesforce, S3, and a grip of other data sources. See all of the sources and destinations available here.
Example Usage
Let’s walk through the process of pulling data from Postgres using a Data Integration Block and then use that data in a Standard Pipeline.
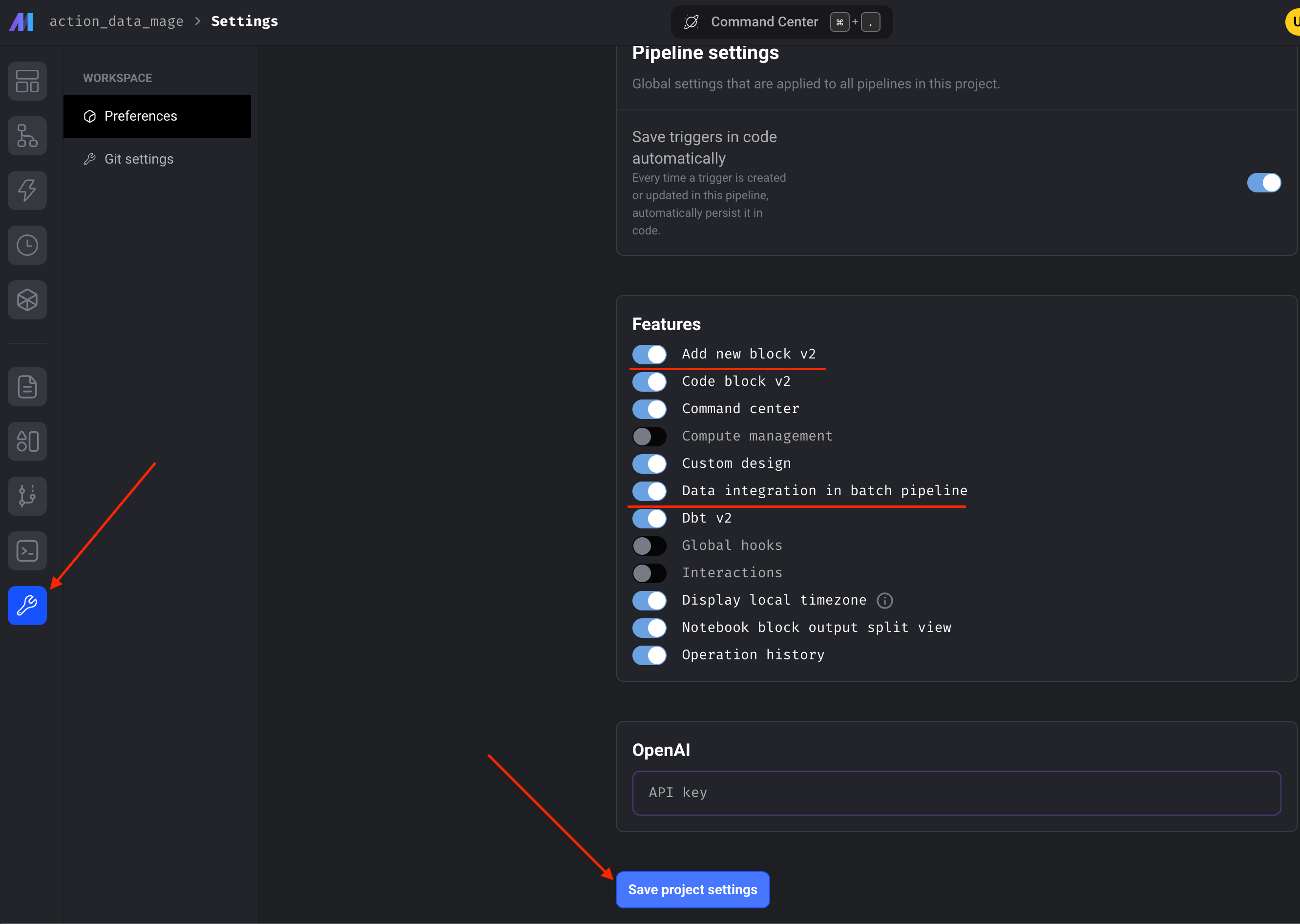
First, we need to enable the preview feature. Navigate to your Project Settings and turn on “Data integration in batch pipeline” and the “Add new block v2” features. Click “Save project settings” after toggling.
Next, create a new standard pipeline and go to the edit screen.
Now, we can add our Postgres Data Integration Block. Click “All blocks” > “Data Loader” > “Sources” > “PostgreSQL” to add the block.

Name the block and click “Save and add.”

You should see this in your pipeline blocks now.

Enter the connection details of the Postgres database from which you want to pull data, and then click “Test connection.”

TIP: I recommend using secrets here rather than plain text credentials. You can reference secrets in the config like this:
password: ”{{ mage_secret_var(‘postgres_password’) }}"See https://docs.mage.ai/development/variables/secrets#using-secrets for more details.
TIP: You can also reference Global Variables in the config. This helps you keep your pipeline generic when using Data Integrations.
schema: “{{ variables(‘schema’) }}If the connection is successful, click “Streams” to select which tables you want to load data from and click “Fetch Streams.” Mage will then pull all the tables that are available to load.

Select the streams/tables from which you would like to pull data. You must then configure those streams by selecting them in the left-hand pane.
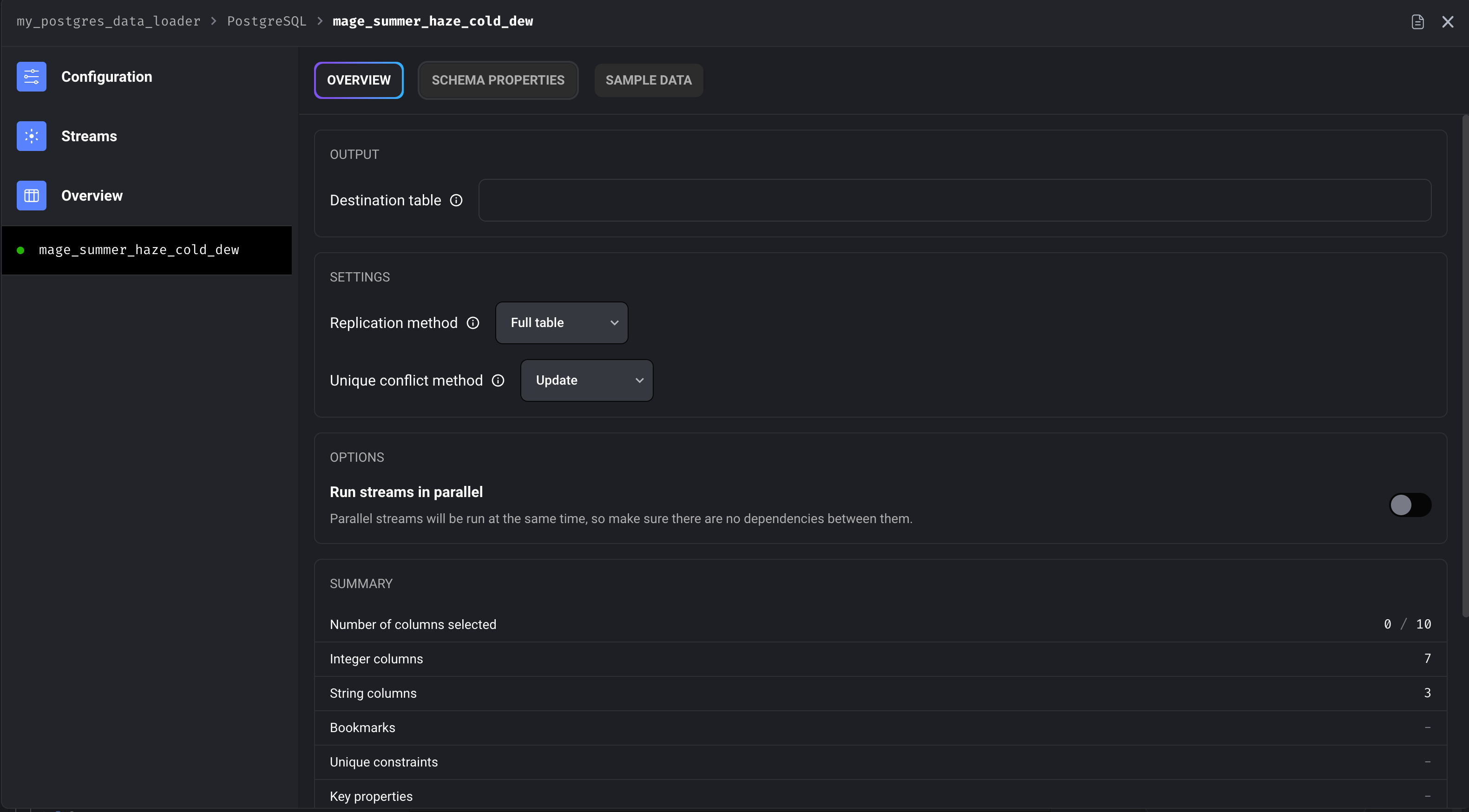
To select the columns you want to read, click “SCHEMA PROPERTIES.”

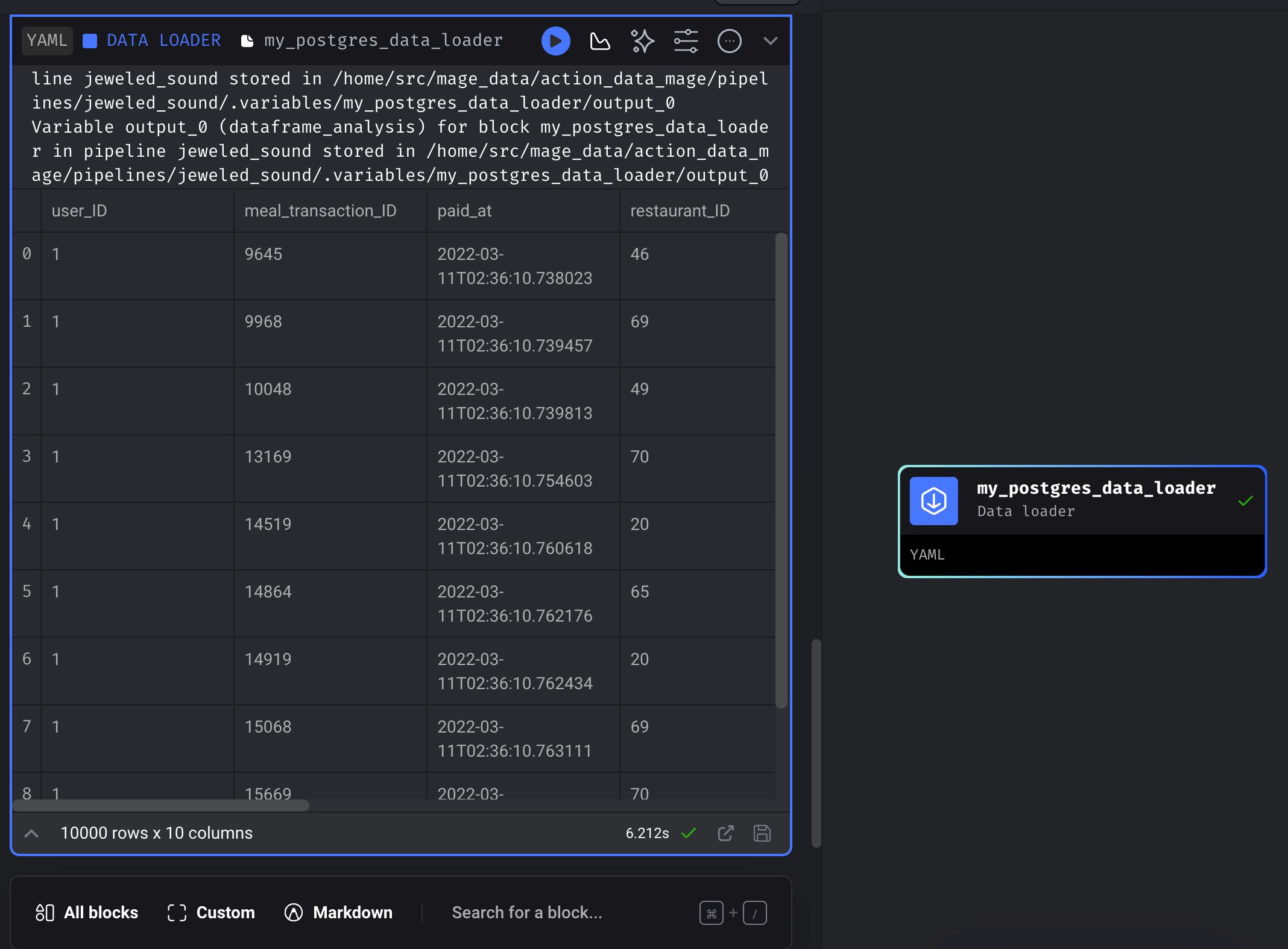
Pull sample data to see if everything works correctly. Click the “SAMPLE DATA” button and then “Refresh sample data”.

Congratulations, you now have a no-code loader for pulling data from Postgres!
Wrapping Up
Using Data Integrations in Standard Pipelines has helped me speed up my pipeline development. Another nice thing is when you run the pipeline via a trigger; data integration blocks will automatically clone themselves and split the data load across the clones. This means they scale well.
Another benefit of using Data Integrations is incremental syncs. You must use both a loader and an exporter Data Integration for it to work. Mage will store a “bookmark” on a specified field and will only sync since that last bookmark in subsequent runs.
Please feel free to comment with any questions or find me on the Mage server and DM me. Happy building!
This is what the world needs, an intuitive tutorial on this!